C++目前在一些领域处于垄断地位,比如数据库内核、高性能网络代理、基础软件设施 等基本都是C/C++的垄断领域,虽然其他语言也有在做,但是生态、性能等都无法企及,其次C/C++有着丰富的生态,很多高级语言也提供了接口可以对接C/C++ (JNI/CGO等) ,这样你可以很方便的将一些底层C/C++库链接到自己的项目中,避免造轮子!本人学习C++目的是为了看懂别人的代码,因为很多优秀的项目都是C++写的,而非我从事C++相关领域开发!
个人觉得C++本身包含了几门语言:面向对象语言 + 内存管理语言 + 模版语言,其中最臭名昭著的就是模版,大量的SFINAE实现,难以理解的报错信息,让很多人讨厌C++,其次就是C++委员会对于各种语法的支持!
本篇文章会长期更新和补充,而且篇幅过长,我平时喜欢把学习语言语法相关的文档归类到一起,所以会存在体积较大的问题,方便平时当作工具书使用,可能有点啰嗦了,这个是我从学习一开始记录的文章,不同阶段理解程度是不一样的!
学习环境 个人觉得如果你是一个新手,一定要选一个利于学习的环境,个人比较推荐新手用 clion(或者vscode+clangd 非常适合非cmake项目或者比较大的项目)!目前C++ 版本应该已经到了C++23了 !编译器的话比较推荐clang,编译工具的话推荐cmake,版本的话目前比较推荐 C++17,不过2023年了更加推荐C++20!camke学习成本并不是太高(bazel复杂度有点高),可以看我写的文章: cmake入门 !
11:STL + 智能指针 14、17 优化了语法和新增部分API,所以如果不用c++20最好的选择就是c++17了! 20 支持了 coroutine(无栈协程)、concept(新版的SFINAE)、模块(目前还没大量使用) 如果你是c++开发同学最好选择自己公司的编译工具和开发规范!C++规范,按照公司的来即可,如果没有的话可以参考Google的:https://github.com/google/styleguide
学习文档的话,语法学习仅建议学习官方文档:https://en.cppreference.com/w/cpp/language, 原因就是内容最全面、分类最具体,如果你东看西看可能概念很模糊 !技巧学习的话我建议多看看开源项目,其次就是看一下经验的书 Effective c++ 和 C++ Template 第二版,实践才是硬道理。
C++的语法应该是没有任何一个语言能超越的,复杂恶心,所以死啃开源项目,啃完就好了,最难理解的就是模版元编程!
从hello world 开始 1 2 3 4 5 6 7 #include <iostream> int main () std::cout << "Hello" << " " << "World!" << std::endl; }
不清楚大家对于上面代码比较好奇的是哪里了?比如说我好奇的是为啥<<就可以输出了, 为啥还可以 << 实现 append 输出? 对,这个就是我的疑问!
思考一下是不是等价于下面这个代码了?是不是很容易理解了就!可以把 operator<< 理解为一个方法名! 具体细节下文会讲解!
1 2 3 4 5 #include <iostream> int main () std::operator <<(std::cout,"Hello" ).operator <<(" " ).operator <<("World!" ).operator <<(std::endl); }
内置类型 注意C++很多时候都是跨端开发,所以具体基础类型得看你的系统环境,常见的基础类型你可以直接在 https://en.cppreference.com/w/cpp/language/types 这里查看 !
char* 和 char[] 和 std::string 本块内容可以先了解一遍,看完本篇内容再回头看一下会理解一些!
字符串在编程中处于一个必不可少的操作,那么C++中提供的 std::string 和 char* 区别在呢了?
简单来说const char* xxx= "字面量" 的性能应该是最高的,因为字面量分配在常量区域,更加安全,但是注意奥不可修改的!
char[]= "字面量" | new char[]{} 分配在栈上或者堆上非常不安全,这种需求直接用 std::vector 或者 std::array 更好!
std::string 在C++11有了移动语意后,性能已经在部分场景优化了很多,进行字符串操作比较多的话介意用这个,别乱用std::string* 。使用 std::string 一般不会涉及到内存安全问题,无非就是多几次拷贝! 如果用指针最好也别用裸指针,别瞎new,可以用智能指针,或者参数[引用]传递!
下面是一个简单的例子,可以参考学习!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 #include <cstring> #include <iostream> using namespace std;const char * getStackStr () char arr[] = "hello world" ; return arr; } const char * getConstStr () const char * arr = "hello world" ; return arr; } const char * getHeapStr () char stack[] = "hello world" ; char * arr = new char [strlen (stack) + 1 ]{}; strcpy (arr, stack); *arr = 'H' ; arr[1 ] = 'E' ; return arr; } std::unique_ptr<std::string> getUniquePtrStr () { auto str = std::unique_ptr<std::string>(new std::string ("hello world." )); str->append (" i am from heap and used unique_ptr." ); return str; } std::string getStdStr () { std::string str = "hello world." ; str += " i am from stack and used copy constructor." ; return str; } int main () char * a = "hello world" ; const char * b = "hello world" ; const char * c = "hello world c" ; printf ("%p\n" , a); printf ("%p\n" , b); printf ("%p\n" , c); char arr[] = "1111" ; cout << getStackStr () << endl; cout << getConstStr () << endl; auto arr1 = getConstStr (); auto arr2 = getConstStr (); printf ("%p\n" , arr1); printf ("%p\n" , arr2); printf ("%p\n" , b); auto arr3 = getHeapStr (); cout << arr3 << endl; delete [] arr3; std::string str = arr1; cout << str << endl; printf ("%p\n" , str.data ()); cout << *getUniquePtrStr () << endl; cout << getStdStr () << endl; }
注意点 关于 x++ 和 ++x 首先学过Java/C的同学都知道,x++ 返回的是x+1之前的值, ++x返回的是x+1后的值! 他俩都可以使x加1,但是他俩的返回值不同罢了!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <iostream> using namespace std;int xadd (int & x) int tmp = x; x = x + 1 ; return tmp; } const int & addx (int & x) x = x + 1 ; return x; } int main () int x = 10 ; int tmp = xadd (x); cout << "x: " << x << ", tmp: " << tmp << endl; x = 10 ; tmp = addx (x); cout << "x: " << x << ", tmp: " << tmp << endl; tmp = tmp + 1 ; cout << "x: " << x << ", tmp: " << tmp << endl; }
引用 (左值/右值/万能引用) 引用本质上就是指针,但是它解决了空指针的问题,我个人觉得他是一个比较完美的解决方案!
下面是一个简单的例子,可以看到引用的效果 (单说引用一般是指的左值引用) 1 2 3 4 5 6 7 8 9 10 11 12 13 void inc (int & a, int inc) a = a + inc; } using namespace std;int main (int argc, char const * argv[]) int a = 1 ; inc (a, 10 ); cout << a << endl; return 0 ; }
其实上面这个例子(inc函数)属于左值引用,为什么叫左值引用,是因为它只能引用 左值(lvalue ) , 你可以理解为左值 是一个被定义类型的变量 ,那么它一定可以被取址(因为左引用很多编译器就是用的指针去实现的), 右值则相反,例如字面量 ; 右值包含纯右值(prvalue ) 和将亡值(xvalue ) (将亡值我个人理解是如果没有使用那么下一步就被回收了,生命到达终点的那种!) 下面是一个左值(lvalue)/右值(rvalue)/万能引用(Universal Reference)在实际开发中的例子 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 #include <unordered_map> #include <string> #include <iostream> #include <shared_mutex> template <typename K, typename V>struct SafeMap {public : template <class T > auto Get (T &&key) std::shared_lock lock (mutex) ; return map[std::forward<T>(key)]; } bool Exist (K &&key) std::shared_lock lock (mutex) ; if (const auto &kv = map.find (key); kv == map.end ()) { return false ; } return true ; } void Put (K key, const V &value) std::unique_lock lock (mutex) ; map[key] = value; } auto Size () std::shared_lock lock (mutex) ; return map.size (); } private : std::unordered_map<K, V> map; std::shared_mutex mutex; }; template <typename T>using StringSafeMap = SafeMap<std::string, T>;int main () std::string key = "1" ; StringSafeMap<int > map; map.Put ("1" , 1 ); std::cout << map.Get ("1" ) << std::endl; std::cout << map.Get (key) << std::endl; if (map.Exist ("1" )) { std::cout << "exist" << std::endl; } else { std::cout << "not exist" << std::endl; } }
有兴趣的可以看文章:
总结:
右值引用可以降低内存拷贝,但是需要实现移动语义! 引用本质上就是指针,所以使用引用一定要注意对象的生命周期,推荐生命周期明确引用传递,不明确值传递(值传递可以通过移动进行优化本质上开销并不大)! 常量左值引用,可传递右值! 万能引用可以减少代码量,尤其是参数多的情况下,万能引用需要配合 std::forword 万能转发使用! 类的初始化函数 类的基本的成员函数 这个是C++ 最难的地方,新手做到知道即可,不建议深挖,无底洞一个,显然禁止拷贝和移动才是最佳选择!
C++ 的类,最基本也会有几个部分组成,就算你定义了一个空的类,那么它也会有(前提你使用了这些操作) ,和Java的有点像!
default constructor: 默认构造函数 copy constructor: 拷贝构造函数 (注意: 编译器默认生成的拷贝构造函数是浅拷贝!) copy assignment constructor: 拷贝赋值构造函数 deconstructor: 析构函数 ! C++11引入了 move constructor (移动构造函数 ) 、 move assigment constructor( 移动赋值构造函数 ),你不定义是不会生成的。 下面例子我是根据此教程 写的,大概可以解释6个函数 https://coliru.stacked-crooked.com/a/ae31c28f852e3220
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 #include <iostream> struct Memory {public : explicit Memory (size_t size) : size_(size), data_(new char[size]) { std::cout << "Memory constructors" << std::endl; } ~Memory () { clearMemory (); std::cout << "Memory deconstructors" << std::endl; } Memory (Memory &from) : size_ (from.size_), data_ (new char [from.size_]) { std::copy (from.data_, from.data_ + from.size_, data_); std::cout << "Memory Copy constructors" << std::endl; } Memory &operator =(const Memory &from) { if (this == &from) { std::cout << "Memory Copy assignment constructors (=)" << std::endl; return *this ; } std::cout << "Memory Copy assignment constructors (!=)" << std::endl; clearMemory (); this ->size_ = from.size_; this ->data_ = new char [from.size_]; std::copy (from.data_, from.data_ + from.size_, data_); return *this ; } Memory (Memory &&from) noexcept : size_ (0 ), data_ (nullptr ) { std::cout << "Memory Move constructors" << std::endl; *this = std::move (from); } Memory &operator =(Memory &&from) noexcept { if (this == &from) { std::cout << "Memory Move Assignment constructors(=)" << std::endl; return *this ; } std::cout << "Memory Move Assignment constructors(!=)" << std::endl; delete [] data_; data_ = from.data_; size_ = from.size_; from.data_ = nullptr ; from.size_ = 0 ; return *this ; } void Set (const char *data, size_t size) if (size > size_) { size = size_; } std::copy (data, data + size, data_); } friend std::ostream &operator <<(std::ostream &out, Memory &from) { if (from.data_ == nullptr ) { return out << "null" ; } return out << from.data_; } private : void clearMemory () if (this ->data_ == nullptr ) { return ; } delete [] this ->data_; this ->data_ = nullptr ; } private : size_t size_{}; char *data_{}; }; Memory getMemory (bool x) { if (x) { Memory mm (16 ) ; mm.Set ("true" , 4 ); return mm; } Memory mm (16 ) ; mm.Set ("false" , 5 ); return mm; } int main () Memory memory1 (20 ) ; memory1.Set ("hello world" , 11 ); std::cout << "memory1: " << memory1 << std::endl; Memory memory2 = memory1; std::cout << "memory2: " << memory2 << std::endl; Memory memory3 (0 ) ; memory3 = memory2; std::cout << "memory3: " << memory3 << std::endl; Memory memory4 = getMemory (true ); std::cout << "memory4: " << memory4 << std::endl; memory3 = getMemory (false ); std::cout << "memory3: " << memory3 << std::endl; Memory memory5 = std::move (memory3); std::cout << "memory3: " << memory3 << std::endl; std::cout << "memory5: " << memory5 << std::endl; return 0 ; }
总结:拷贝可以避免堆内存随意引用问题,比如我定义了A对象,此时我在A对象上分配了10M空间,此时B对象拷贝自我,那么此时B引用了A的10M内存,此时A/B回收的时候到底要清理A还是B的10M内存了? 第二个就是移动解决的问题,对于一些右值可能会存在冗余拷贝的问题,此时就可以使用移动优化内存拷贝。 本质上这些构造函数都是为了解决一个问题内存分配!!
初始化列表 这里我们要知道一点就是 C++ 类的初始化内置类型(builtin type)是不会自动初始化为0的,但是类类型(非指针类型)的话却会自动调用默认构造函数,具体为啥了,兼容C,不然会很慢,因为假如你要初始化一个类,例如定义了10个内置类型的字段,我需要10次赋值调用才能把10个字段初始化成0,而不初始化只需要开辟固定的内存空间即可,可以大大提高代码运行效率!
大部分情况下都是推荐使用初始化列表的!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 #include <iostream> using namespace std;class Demo { public : int id; Demo () { cout << "init demo" << endl; } }; class Info { public : int id; long salary; Demo wrapper; }; int main () Info info; cout << info.id << endl; cout << info.wrapper.id << endl; int x; cout << x << endl; Info* infop; cout << infop << endl; cout << "======= C++11 初始化列表 " << endl; Info info1{}; cout << info1.id << endl; cout << info1.wrapper.id << endl; int x1{}; cout << x1 << endl; Info* infop1{}; cout << infop1 << endl; }
类的初始化列表:
类的初始化写法 C++11 就下面这三种写法
( expression-list )小括号括起来的表达式列表= expression 表达式{ initializer-list } 大括号括起来的表达式列表,C++11比较推荐这种写法然后这三种写法大题分为了几大类,这几大类主要是为了区分吧,我个人觉得就是语法上的归类,主要是cpp历史包袱太重了,其次追求高性能,进而分类了很多初始化写法,具体可以看官方文档: https://en.cppreference.com/w/cpp/language/initialization !
类的多态 前期先掌握基本语法吧,实际用到的时候再深入学习,类的继承在C++中特别复杂,因为会涉及到模版、类型转换、虚函数、析构函数,注意事项非常多!
继承 c++的继承非常复杂,底层设计以及各种细节,所以我单独写了一篇文章: C++继承的底层设计
基类 base class ,基类需要把析构函数设置为虚函数,派生类 derived class,基类 和 派生类是相对关系 三种继承方式: public: 基类的 public 和 protected 成员的访问属性在派生类中保持不变(传递性),但基类的 private 成员不可直接访问 protect: 基类的 public 和 protected 成员都以 protected 身份出现在派生类中(传递性),但基类的 private 成员不可直接访问 private: 基类的 public 和 protected 成员都以 private 身份出现在派生类中(传递性),但基类的 private 成员不可直接访问 总结:public 一劳永逸,protect、private 的话会修改基类的访问属性。业务中一般用public,不想对外暴露基类除外 struct 默认继承是public , class 默认继承是private 多写写代码尝试下,就行了 使用虚继承可以降低内存开销,解决多继承的二义性问题 具体例子可以看: override 、final override(重写) 和 overload(重载) 区别在于 override 是继承引入的概念!
这俩修饰词主要是解决继承中重写的问题!
类被修饰为 final 1 2 3 4 5 6 7 8 class A final { public : void func () "我不想被继承" << endl; }; }; class B : };
方法被修饰为 final 1 2 3 4 5 6 7 8 9 class A { public : virtual void func () final "我不想被继承" << endl; }; }; class B : public : void func () };
方法修饰为 override 1 2 3 4 5 6 class A {}; class B : void func () override };
protected public 和 private其实没多必要介绍, 但是涉及到继承,仅允许我的子类访问那么就需要protected关键词了 ,区别于Java的protected.
friend friend (友元)表示外部方法可以访问我的private/protected变量, 正常来说我定义一个一些私有的成员变量,外部函数调用的话,是访问不了的,但是友元函数可以,例如下面这个case:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> class Data { friend std::ostream& operator <<(std::ostream& os, const Data& c); private : int id{}; std::string name; }; std::ostream& operator <<(std::ostream& os, const Data& c) { os << "(Id=" << c.id << ",Name=" << c.name << ")" ; return os; } int main () std::cout << Data{} << std::endl; }
指针的一些细节 注意:别瞎new指针, new了地方要么用智能指针自动回收,要么用delete手动回收! 手动new的一定会分配在堆上,所以性能本身就不高,推荐用智能指针 + raii !
什么叫指针,你可以理解为就是一个long类型的值,但是呢这个long类型的值是一个内存地址,你可以通过操作这个内存地址进行 获取值(因为指针是有类型的),修改内存等操作!
在C/C++ 语言中,表示指针很简单,例如 int* ptr 表示ptr是一个int类型的指针 或者 一个int类型的数组!c++ 判断指针为空用 nullptr !
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int main () int x = 1 ; int y = 2 ; long yp = (long )(&y); int *xp = (int *)((yp) + 4 ); *xp = 100 ; std::cout << x << std::endl; }
例子1: 数组与指针 C++/C 中数组和指针最奇妙,原因是 数组 和 指针 基本概念等价,因为两者都是指向内存的首地址,区别在于数组名定义了数组的长度,但是指针没有数组长度的概念,因此我们无法通过一个指针获取数组长度!
类似于下面这个例子, arr 是一个数组,p1、p2是一个数组指针
1 2 3 4 5 6 7 8 9 10 11 12 int main (int argc, char const * argv[]) int arr[] = {1 , 2 , 3 , 4 , 5 }; int * p1 = arr; int * p2 = &arr[0 ]; cout << "sizeof(arr)=" << sizeof ", sizeof(arr[1])=" << sizeof 1 ]) << ", sizeof(p1)=" << sizeof ", sizeof(p2)=" << sizeof cout << "arr len=" << sizeof sizeof 0 ]) << endl; cout << "arr=" << arr << ", p1=" << p1 << ", p2=" << p2 << endl; for (int i = 0 ; i < 5 ; i++) { cout << "i=" << i << ", (arr+i)=" << arr + i << ", (p1+i)=" << p1 + i << ", arr[i]=" << arr[i] << ", *(p1+i)=" << *(p1 + i) << endl; } return 0 ; }
输出
1 2 3 4 5 6 7 8 sizeof(arr)=20, sizeof(arr[1])=4, sizeof(p1)=8, sizeof(p2)=8 arr len=5 arr=0x7ff7bd9999f0, p1=0x7ff7bd9999f0, p2=0x7ff7bd9999f0 i=0, (arr+i)=0x7ff7bd9999f0, (p1+i)=0x7ff7bd9999f0, arr[i]=1, *(p1+i)=1 i=1, (arr+i)=0x7ff7bd9999f4, (p1+i)=0x7ff7bd9999f4, arr[i]=2, *(p1+i)=2 i=2, (arr+i)=0x7ff7bd9999f8, (p1+i)=0x7ff7bd9999f8, arr[i]=3, *(p1+i)=3 i=3, (arr+i)=0x7ff7bd9999fc, (p1+i)=0x7ff7bd9999fc, arr[i]=4, *(p1+i)=4 i=4, (arr+i)=0x7ff7bd999a00, (p1+i)=0x7ff7bd999a00, arr[i]=5, *(p1+i)=5
结论:
数组、数组指针其实都是 数组的第一个元素对应的内存地址(指针) 数组+1 和 指针+1 ,其实不是简单的int+1的操作,而是偏移了类型的长度,原因是 指针是有类型的,且指针默认重载了 + 运算符 ! 数组是可以获取数组的长度的,但是数组指针不可以! 注意:
数组delete 和 delete[] 需要特别注意,因为 delete[]与new[] 成对出现,以及 delete和new成对出现 例子2: 数组长度 通常,我们不可能在main函数里写代码,是不是,我们更多都是函数调用,那么问题来了? 函数调用如何安全的操作呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int * get_array () int * arr = new int [12 ]; for (int i = 0 ; i < 12 ; i++) { *(arr + i) = i + 1 ; } return arr; } int main (int argc, char const * argv[]) int * arr = get_array (); for (int i = 0 ; i < 12 ; i++) { cout << *(arr + i) << endl; } return 0 ; }
问题: 如何获取arr的长度的呢? 显然是不可以获取的!
例子3: 常量指针 常量指针(Constant Pointer ),表示的是指针指向的内存(内容)不可以修改,也就是说 *p 不可以修改,但是 p可以修改 1 2 int const * p; const int * p;
例子
1 2 3 4 5 6 7 8 9 10 11 12 13 int main (int argc, char const * argv[]) using namespace std; int x = 10 ; int * p2 = new int ; const int * p = &x; p = p2; cout << "p: " << *p << endl; return 0 ; }
指针常量(pointer to a constant :指向常量的指针),表示 p 不可以修改,但是 *p 可以修改 例子
1 2 3 4 5 6 7 8 9 10 11 12 13 int main (int argc, char const * argv[]) using namespace std; int x = 10 ; int * p2 = new int ; int * const p = &x; *p = 20 ; cout << "p: " << *p << endl; return 0 ; }
指向常量的常量指针 总结 大部分case都是使用常量指针,因为指针传递是不安全的,如果我们的目的是不让指针去操作内存 ,那么我们就用 常量指针 ,对与指针本身来说就是一个64位的int它变与不变你不用管!
补充一些小点 指针到底写在 类型上好 int* p,还是变量上好 int *p, 没有正确答案,我是写Go的所以习惯写到类型上!具体可以看 https://www.zhihu.com/question/52305847?rf=21136956 指向成员的指针运算符: (比较难理解,个人感觉实际上就是定义了一个指针 alies ).* 和 ->* ::* 智能指针 在C++11中存在四种智能指针:std::auto_ptr,std::unique_ptr,std::shared_ptr,std::weak_ptr,
auto_ptr : c++98 中提供了,目前已经不推荐使用了
unique_ptr: 这个对象没有实现拷贝构造函数,所以我们用的时候只能用 std::move 进行移动赋值 ,经常使用 !
shared_ptr: 其实类似于GC语言的对象,他通过引用计数【循环引用会导致内存泄露】,实现自动回收,经常使用 吧!
weak_ptr: 本质上就是解决 shared_ptr 循环引用的问题,它持有 shared_ptr,但是不会使得shared_ptr引用计数增加,很少使用 吧!
c++14新增了make_unique 的api,这里的原理会涉及到 std::move 和 std::forward 函数相关知识, 有兴趣可以了解下 完美转发和万能引用,以及移动语意!
std::unique_ptr 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Test { public : explicit Test (int x_) : x(x_) { ~Test () { std::cout << "release: " << x << std::endl; } public : int x; }; Test* newTestFunc (int x) { return new Test (x); } int main () std::unique_ptr<Test> test1 = std::unique_ptr<Test>(new Test (1 )); auto test2 = std::move (test1); std::cout << "test1 is null ptr: " << (test1 == nullptr ) << std::endl; std::cout << "test2.x: " << test2->x << std::endl; test2.reset (new Test (2 )); Test* test2_ = test2.release (); std::cout << "test2_->x: " << test2_->x << std::endl; delete test2_; auto test = std::unique_ptr<Test>(newTestFunc (3 )); }
std::shared_ptr shared_ptr 实际上基本已经对标主流的垃圾回收语言了,它使用引用计数的方式实现了垃圾回收!
shared_ptr 会存储一个引用计数器+指针,每次拷贝都会使得计数器+1然后再拷贝数据,当调用析构函数(或者 reset函数)的时候会使得计数器-1;当为0的时候会直接会去释放指针!所以原理并不复杂吧!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 struct AStruct ;struct BStruct ;struct AStruct { std::shared_ptr<BStruct> bPtr; ~AStruct () { std::cout << "AStruct is deleted!" << std::endl; } }; struct BStruct { int Num; ~BStruct () { std::cout << "BStruct is deleted!" << std::endl; } }; void setAB (const std::shared_ptr<AStruct> &ap) std::shared_ptr<BStruct> bp (new BStruct{}) ; std::cout << "bp->count[0]: " << bp.use_count () << std::endl; bp->Num = 111 ; ap->bPtr = bp; std::cout << "bp->count[1]: " << bp.use_count () << std::endl; std::cout << "bp->count[1.1]: " << ap->bPtr.use_count () << std::endl; } void Test () std::shared_ptr<AStruct> ap (new AStruct{}) ; setAB (ap); std::cout << ap->bPtr->Num << std::endl; std::cout << "bp->count[2]: " << ap->bPtr.use_count () << std::endl; } int main () Test (); }
但是这个也注定有一个陷阱,就是循环引用无法解决!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 struct AStruct ;struct BStruct ;struct AStruct { std::shared_ptr<BStruct> bPtr; ~AStruct () { std::cout << "AStruct is deleted!" << std::endl; } }; struct BStruct { std::shared_ptr<AStruct> aPtr; ~BStruct () { std::cout << "BStruct is deleted!" << std::endl; } }; void TestLoopReference () std::shared_ptr<AStruct> ap (new AStruct{}) ; std::shared_ptr<BStruct> bp (new BStruct{}) ; ap->bPtr = bp; bp->aPtr = ap; } int main () TestLoopReference (); }
std::weak_ptr weak_ptr 本质上并不能算的上是一个智能指针,只能说是为了解决 shared_ptr 循环引用的问题 [不能根本解决],weak_ptr相当于拷贝了一份 shared_ptr, 但是引用次数并不会增加,为此假如 shared_ptr 已经被释放了,那么weak_ptr也会指向空指针!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 struct AStruct ;struct BStruct ;struct AStruct { std::weak_ptr<BStruct> bPtr; ~AStruct () { std::cout << "AStruct is deleted!" << std::endl; } }; struct BStruct { std::weak_ptr<AStruct> aPtr; int Num; ~BStruct () { std::cout << "BStruct is deleted!" << std::endl; } }; void TestLoopReference () std::shared_ptr<AStruct> ap (new AStruct{}) ; std::shared_ptr<BStruct> bp (new BStruct{}) ; bp->Num = 1 ; ap->bPtr = bp; bp->aPtr = ap; std::cout << "BStruct.Num: " << ap->bPtr.lock ()->Num << std::endl; } int main () TestLoopReference (); }
智能指针和数组 针对于数组指针, 需要自己定义delete函数 https://coliru.stacked-crooked.com/a/83d4d163afb6cdd8 针对于数组,无需特殊处理 https://coliru.stacked-crooked.com/a/b3e9c0103382fe3b 1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <memory> int main () std::shared_ptr<Int[]> data{}; data.reset (new Int[10 ]); std::shared_ptr<Int> data2{}; data.reset (new Int[10 ], [](auto p) { delete [] p; }); }
内存回收的一些思考 虽然C++中提供了 raii 和 智能指针,但是内存的频繁分配和频繁销毁,会给cpu造成一些开销(性能慢、延时高等),那么业务中经常遇到那种巨型结构进行序列化反序列化,那么业内也有一些解决方案,就是使用 arena ,具体可以参考 关键词 const C++的 const 表达的意思是只读的意思,就是不可变的意思!
这里主要是介绍一个双重指针,其他疑问可以看这个链接: https://www.zhihu.com/question/433076446 ! 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> void foo1 () using namespace std; int * x = new int 10 ); int * const * p = &x; cout << **p << endl; **p = 100 ; cout << **p << endl; } void foo2 () using namespace std; const int * x = new int 10 ); const int ** p = &x; cout << **p << endl; *p = new int 11 ); cout << **p << endl; } int main () foo1 (); foo2 (); }
const 可以修饰方法的返回值 1 2 3 4 5 6 7 const char * getString () return "hello" ; }int main () auto str = getString (); *(str + 1 ) = 'a' ; return 0 ; }
const 修饰方法的参数 1 2 3 4 5 6 void printStr (const char * str) int main () printStr ("1111" ); return 0 ; }
const 修饰方法, 表示此方法是一个只读的函数 1 2 3 4 5 6 7 class F { private : int a; public : void foo () const this ->a = 1 ; } };
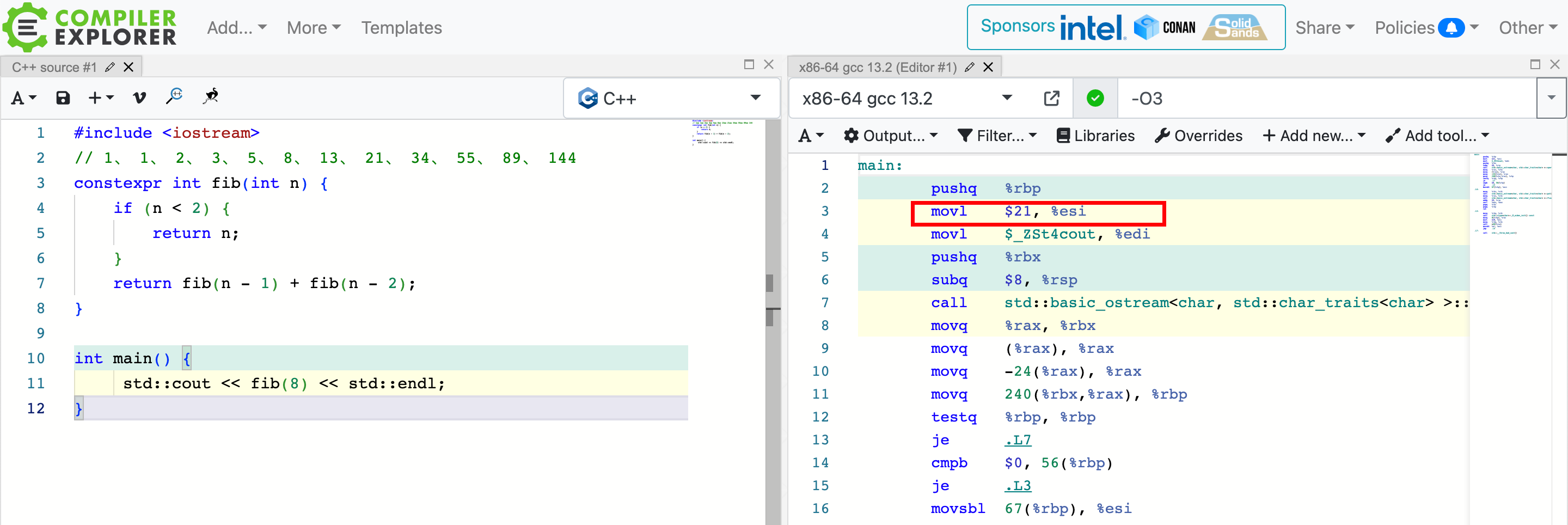
constexpr constexpr 常量表达式,就是它可以在编译后直接替换为计算所得的值!可以看下面这个例子,直接计算出 fib(6) 的值直接赋值给了esi (参数一) !
constexpr 目前已经是非常成熟的能力了,但是它会给编译器带来比较大的压力!
C++11:仅支持简单的常量表达式
C++14:支持逻辑语句
C++17:支持Lambda
参考文章
说实话,一堆花里胡哨的东西你很难理解它的实际用途,像上面这种常量表达式计算,人家编译器可能直接给你优化了,完全不需要你申明 consteptr
主要实用的用途就是:
让编译器提前优化代码(提前的意思表示可能未来编译器就优化了),类似于上面那个纯粹的计算函数
编译时期进行 static_assert,进行一些类型、常量检测
编译器进行条件判断,减少代码量,但是实际上这个例子可以用 cpp17的 fold expression
1 2 3 4 5 6 7 8 9 10 11 12 13 14 template <typename T, typename ... Args>constexpr void print (T t, Args ... args) std::cout << t << " " ; if constexpr (sizeof ...(args) > 0 ) print (args ...); } if constexpr (sizeof ...(args) == 0 ) std::cout << "\n" ; } } int main () print ("1" , "2" , "3" ); }
static static 主要是内存分配的问题,在程序初始化阶段会有一个静态内存区域专门存储静态变量的,其次静态局部变量可以保证多线程安全(c++11后)!
注意: c++中static定义在头文件中会被初始化多次,不要在头文件中定义全局static变量 ,别误以为是static作用域失效了!
全局 静态变量、静态方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <fmt/core.h> namespace example {static int NumberX = 100 ;static int NumberY = 200 ;static int NumberZ = NumberY + 300 ;static void print () fmt::print ("x: {}, y: {}, z: {}\n" , NumberX, NumberY, NumberZ); } class Class {public : static void print () static const int x; static int y; static int z; }; } #include <fmt/core.h> const int example::Class::x = 1 ;int example::Class::y = z + 2 ;int example::Class::z = 2 ;void example::Class::print () { fmt::print ("x: {}, y: {}, z: {}" , x, y, z); } int main () example::print (); example::Class::print (); }
全局静态方法和静态变量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <iostream> int inc () static int sum = 0 ; return ++sum; } int main (int argc, char const * argv[]) std::cout << inc () << std::endl; std::cout << inc () << std::endl; return 0 ; }
模版的静态变量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class A {public : static int num; }; int A::num = 100 ;class B :public A {};class C :public A {};template <class T >class AA {public : static int num; }; template <class T >int AA<T>::num = 1 ;class BB :public AA<BB> {};class CC :public AA<CC> {};int main () printf ("%p\n" , &B::num); printf ("%p\n" , &C::num); printf ("%p\n" , &BB::num); printf ("%p\n" , &CC::num); }
写一个单例对象 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <absl/base/call_once.h> #include <fmt/core.h> template <class T >class ThreadSafeSingleton {public : static T &get () absl::call_once (ThreadSafeSingleton<T>::create_once_, &ThreadSafeSingleton<T>::Create); return *ThreadSafeSingleton<T>::instance_; } protected : static void Create () new T (); } static absl::once_flag create_once_; static T *instance_; }; template <class T >absl::once_flag ThreadSafeSingleton<T>::create_once_; template <class T >T *ThreadSafeSingleton<T>::instance_ = nullptr ; template <class T >class ConstSingleton {public : static T &get () static T *t = new T (); return *t; } }; struct ExampleStruct { std::string name; }; using ExampleStructSingleton = ThreadSafeSingleton<ExampleStruct>;using ExampleStructConstSingleton = ConstSingleton<ExampleStruct>;int main () ExampleStructSingleton::get ().name = "hello world" ; fmt::print ("name = {}\n" , ExampleStructSingleton::get ().name); ExampleStructConstSingleton::get ().name = "hello world" ; fmt::print ("name = {}\n" , ExampleStructConstSingleton::get ().name); }
extern extern C 主要是解决C++ -> C 链接方式不得同,以及C与C++函数互相调用的问题其他待补充! auto 和 decltype 看这里之前建议先学习模版
auto 实际上是大部分高级语言现在都有的一个功能,就是类型推断,c++11引入auto 原因也是因为模版, 其次更加方便!
decltype 本质上也是类型推断,但是它与 auto 是俩场景,解决不同的场景的问题,非常好用,decltype并不会真正的调用函数,只是获取函数的类型,非常好用,尤其是面对复杂模版的时候!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 template <typename T, typename U>auto add (T t, U u) -> decltype (t + u) using Sum = decltype (t + u); Sum s = t + u; s = s + 1 ; return s; } int main () auto num = add (float 1.1 ), int 1 )); cout << num << endl; return 0 ; }
上面代码,如果没有 decltype 很难去实现,如果仅用模版根本无法推断出到底返回类型是啥,可能是int 也可能是 float !
注意:
decltype 最难的地方还是在于它保留了 左值/右值信息,这个就给编程带来了一定的难度! c++14 有更精简的语法,具体可以看c++14语法 using 和 typedef 看这里之前先学习模版
虽然大部分case两者差距不大,using 这里主要解决了一些case 语法过于复杂的问题!
例如 typedef 无法解决模版的问题,只能依赖于类模版去实现!
using 更加方便!
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <iostream> #include <list> template <typename T, template <typename > class MyAlloc =using MyAllocList = std::list<T, MyAlloc<T>>;int main () auto my_list = MyAllocList<int >{1 , 2 , 3 , 4 }; for (auto item : my_list) { cout << item << endl; } return 0 ; }
如果用typedef 我们只能定义一个 类
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <iostream> #include <list> template <typename T, template <typename > class MyAlloc =struct MyAllocList2 { public : typedef std::list<T, MyAlloc<T>> type; }; int main () auto my_list_2 = MyAllocList2<int >::type{1 , 2 , 3 , 4 }; return 0 ; }
switch & break 其实我这里就想说一点,就是switch当匹配到case后,如果case没有执行break,会继续执行下面的case,已经不管case是否匹配了!!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> int main () int x = 2 ; switch case 1 : { std::cout << "1" << std::endl; } case 2 : { std::cout << "2" << std::endl; } case 3 : { std::cout << "3" << std::endl; } } }
break用法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <iostream> int main () int x = 2 ; switch case 1 : { std::cout << "1" << std::endl; } case 2 : { std::cout << "2" << std::endl; } break ; case 3 : { std::cout << "3" << std::endl; } } }
typename C++ 为什么要引入一个 typename 关键词,不光光是申明一个 模版参数列表 这么简单,其次更重要的是申明模版依赖(dependency),需要配合 template 关键词使用!在模版元编程中大量使用!
比较感兴趣的两个话题:
typename和class有着相同的能力在模版这里,但是typename更多的是为了支持模版!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <spdlog/spdlog.h> struct Test { std::string name; }; template <>struct fmt : static auto format (const Test &my, fmt::format_context &ctx) -> decltype (ctx.out()) return format_to(ctx.out (), "[test name={}]" , my.name); } }; template <typename T>constexpr auto has_const_formatter (T t) -> decltype (typename fmt::formatter<T>().format(std::declval<const T &>(), std::declval<fmt::format_context &>()), true ) return true ; } int main () std::cout << has_const_formatter<>(Test{}) << std::endl; }
操作符重载(运算符重载) 本质上操作符重载就是可以理解为方法的重载,和普通方法没啥差别!但是C++支持将一些 一元/二元/三元的运算符进行重载!
实际上运算符重载是支持 类内重载、类外重载 的,两者是等价的!但是有些运算符必须要类内重载,例如 = 、[]、()、-> 等运算符必须类内重载!
这也就是为啥 ostream 的 <<仅仅重载了部分类型,就可以实现输出任意类型了(只要你实现了重载),有别于一些其他语言的实现了,例如Java依赖于Object#ToString继承,Go依赖于接口实现等!运算符重载的好处在于编译器就可以做到检测!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <iostream> using namespace std;class Complex { private : int re, im; public : Complex (int re, int im) : re (re), im (im) { } Complex operator +(const Complex& other) { return Complex (this ->re + other.re, this ->im + other.im); } void print () cout << "re: " << re << ", im: " << im << endl; } }; int main (int argc, char const * argv[]) Complex a = Complex (1 , 1 ); Complex b = Complex (2 , 2 ); Complex c = a + b; c.print (); return 0 ; }
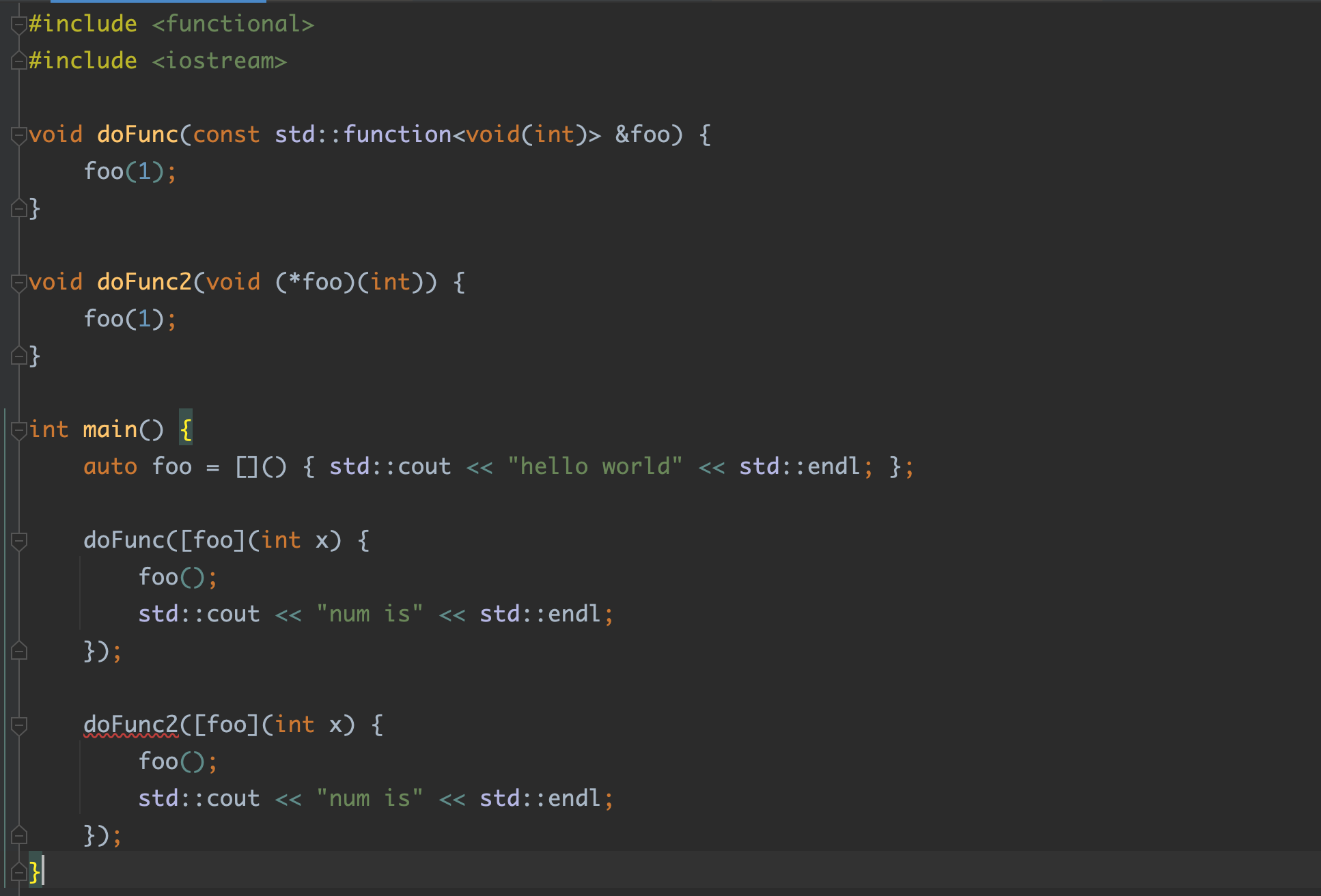
lambda 首先lambda 其实在函数式编程很常见,但实际上我个人还是不理解,如果为了更短的代码,我觉得毫无意义,只不过是一个语法糖罢了,本质上C++的Lambda就是语法糖,编译后会发现实际上是一个匿名的仿函数!
那么什么才是lambda?我觉得函数式编程,一个很强的概念就是(anywhere define function)任意地方都可以定义函数,例如我现在经常写Go,我定义了一个方法,我需要用到某个方法,但是呢这个作用范围我不想放到外面,因为外面也用不到。因此分为了立即执行函数和变量函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 type Demo struct { Name *string } func foo () newDemo := func (v string ) *Demo return &Demo{ Name: func (v string ) *string if v == "" { return nil } return &v }(v), } } demo1 := newDemo("1" ) demo2 := newDemo("" ) fmt.Println(demo1.Name) fmt.Println(demo2.Name) }
那么换做C++,我怎么写呢? 是的如此强大的C++完全支持, 哈哈哈哈!注意是C++11 !
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 struct Demo { public : const char * name; Demo (const char * name) : name (name) { } }; void foo () auto newDemo = [](const char * name) { return new Demo ([&] { if (*name == '\0' ) { const char * null; return null; } return name; }()); }; Demo* d1 = newDemo ("111" ); Demo* d2 = newDemo ("" ); std::cout << d1->name << std::endl; std::cout << d2->name << std::endl; }
基于上面的例子我们大概知道了如何定义一个 变量的类型是函数 , 其次如何定义一个立即执行函数!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 int add1 (int x, int y) auto lam = [&]() { x = x + 1 ; y = y + 1 ; return x + y; }; return lam (); } int add2 (int x, int y) auto lam = [=]() { return x + y; }; return lam (); } int add3 (int x, int y) std::function<int int )> lam = [&x](int y) { x = x + 1 ; return x + y; }; return lam (y); }
1 2 3 4 5 6 7 8 9 10 11 12 13 int main (int argc, char const * argv[]) std::function<int int , int )> lam = [](int a, int b) { return a + b; }; std::cout << lam (1 , 9 ) << " " << lam (2 , 6 ) << std::endl; [] { std::cout << "立即执行函数" << std::endl; }(); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 std::function<void () > print (std::string str) throw (const char *) { if (str == "" ) { throw "str is empty" ; } return [=] { std::cout << "print: " << str << std::endl; }; } int main (int argc, char const * argv[]) try { print ("" )(); } catch const char * v) { std::cout << "函数执行失败, 异常信息: " << v << std::endl; } print ("abc" )(); return 0 ; }
注意点:
区别于仿函数,仿函数是重载了()运算符,仿函数本质上是类,但是C++11引入了std::function 也就是 lamdba 简化了仿函数,所以C++11 不再推荐仿函数了! 区别于函数指针 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <algorithm> #include <iostream> #include <vector> class NumberPrint { public : explicit NumberPrint (int max) : max(max){ void operator () (int num) const if (num < max) { std::cout << "num: " << num << std::endl; } }; private : int max; }; void printVector (std::vector<int >&& vector, void (*foo)(int )) begin (), vector.end (), foo); }void printNum (int num) "num: " << num << std::endl; }int main () printVector (std::vector<int >{1 , 2 , 3 , 4 }, printNum); auto arr = std::vector<int >{1 , 2 , 3 , 4 }; std::for_each(arr.begin (), arr.end (), NumberPrint (3 )); }
函数指针的致命缺陷, 就是函数指针不支持捕获参数,所以最好别用函数指针,除非对接C!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <functional> #include <string> #include <iostream> template <typename T>struct Handler { using c_function = std::string (*)(T); std::string operator () (T x) { return "Handler<T>(x)" ; }; }; template <>struct Handler <int > { using c_function = std::string (*)(int ); std::string operator () (int x) { return "Handler<int>(" + std::to_string (x) + ")" ; }; }; void print (int num, const std::function<std::string(int )>& handler) std::cout << "print: " << handler (num) << "\n" ; } void print_c (int num, std::string (*handler)(int )) std::cout << "print_c: " << handler (num) << "\n" ; } int main () std::string name = "lambda" ; print (1 , [&](auto x) { return name + "(" + std::to_string (x) + ")" ; }); print (2 , Handler<int >{}); print_c (3 , [](int x) -> std::string { return "c_lambda (" + std::to_string (x) + ")" ; }); }
枚举 C++的枚举继承了C,也就是支持 enum 和 enum class,两者的区别主要是在于作用范围的不同, 例如下面 Child 和 Student 都定义了 Girl 和 Body,如果不是 enum class 的话则会报错!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <iostream> #include <map> enum class Child :char { Girl, Boy = 1 , }; const static std::map<Child, std::string> child_map = {{ Child::Girl, "Girl" , }, { Child::Boy, "Boy" , }}; std::ostream& operator <<(std::ostream& out, const Child& child) { auto kv = child_map.find (child); if (kv == child_map.end ()) { out << "Unknown[" << int "]" ; return out; } out << kv->second; return out; } enum class Student { Girl, Boy }; using namespace std;int main () Child x = Child::Boy; cout << x << endl; cout << int cout << Child (100 ) << endl; }
模版 我自己写了篇文章有兴趣的可以读一下:C++模版
类/函数模版 类模版支持全特化和偏特化,函数模版仅支持全特化
注意:在C++中,特化的模板并不能从其通用模板(也就是基模板)”继承”成员
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <iostream> #include <unordered_map> #include <map> #include <vector> template <typename K, typename V, template <typename ...> class Map_ =struct Map { using type = Map_<K, V>; V& operator [](const K& k) { return map_[k]; }; private : Map_<K, V> map_{}; }; template <template <typename ...> class Container , typename T >void PrintContainer (const Container<T>& c) for (const auto & v : c) { std::cout << v << ' ' ; } std::cout << '\n' ; } template <template <typename ...> class Map , typename K , typename V >void PrintMap (const Map<K, V>& c) for (const auto & v : c) { std::cout << v.first << ':' << v.second << ' ' ; } std::cout << '\n' ; } template <>void PrintMap (const std::map<int , int >& c) for (const auto & v : c) { std::cout << "i" << v.first << ':' << v.second << ' ' ; } std::cout << '\n' ; } int main () Map<std::string, int > map; map["11" ] = 1 ; std::cout << map["11" ] << std::endl; Map<std::string, int , std::map>::type ordered_map; PrintContainer (std::vector<int >{1 , 2 , 3 }); PrintMap (std::map<int , int >{{1 , 1 }, {2 , 2 }}); PrintMap (std::map<std::string, int >{{"1" , 1 }, {"2" , 2 }}); }
可变参数模版 c++如果不使用模版是不支持可变参数的,因此如果实现可变参数必须要通过模版,区别于别的语言,其实像Go这种语言可变参数仅是一个语法糖,最终还是会实例化成List的!下面是C++模版的例子!
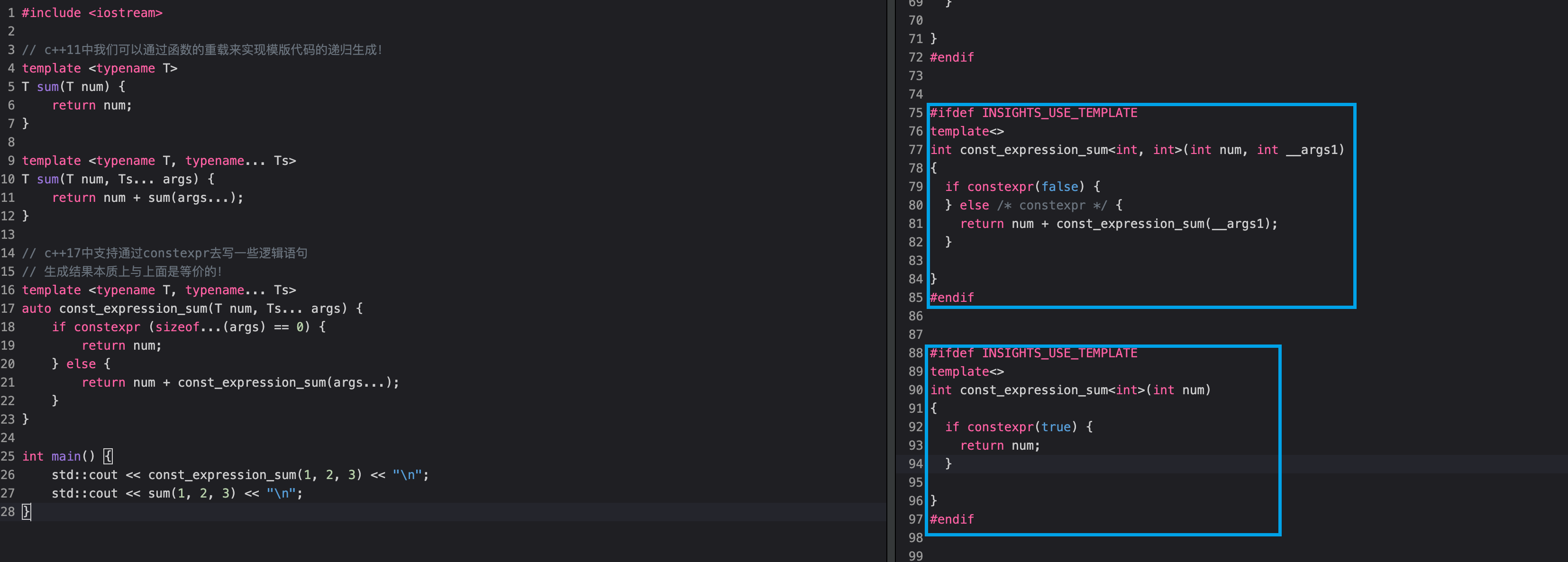
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <iostream> template <typename T>T sum (T num) { return num; } template <typename T, typename ... Ts>T sum (T num, Ts... args) { return num + sum (args...); } template <typename T, typename ... Ts>auto const_expression_sum (T num, Ts... args) if constexpr (sizeof ...(args) == 0 ) return num; } else { return num + const_expression_sum (args...); } } int main () std::cout << const_expression_sum (1 , 2 , 3 ) << "\n" ; std::cout << sum (1 , 2 , 3 ) << "\n" ; }
具体会生成一个类似于下面这个代码,有兴趣的同学可以通过这个网站编译看一下 https://cppinsights.io/
C++17 fold expression (折叠表达式) 官方文档: https://en.cppreference.com/w/cpp/language/fold
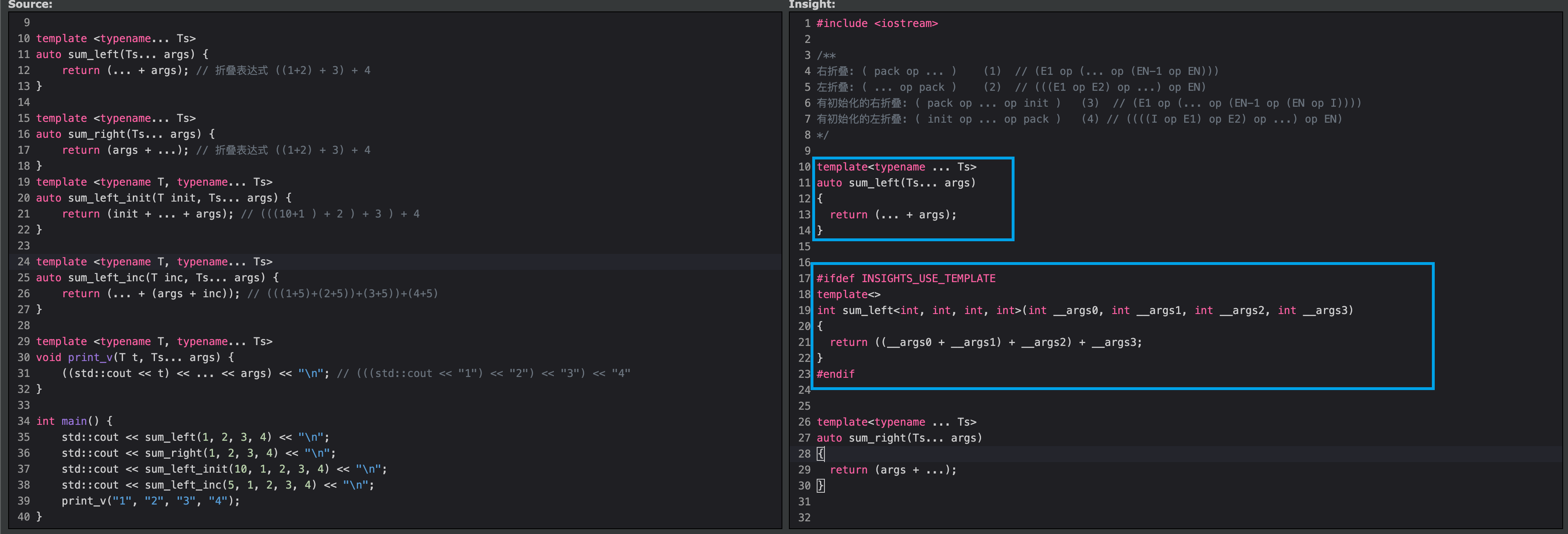
上面的可变参数模版我们发现一个问题需要大量生成函数,那么如果我n个可变参数多就会生成n个函数,会导致代码的膨胀,因此C++17提供了折叠表达式完美的解决了此问题!说实话我感觉这玩意特别像Python的列表推到式 !
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <iostream> template <typename ... Ts>auto sum_left (Ts... args) return (... + args); } template <typename ... Ts>auto sum_right (Ts... args) return (args + ...); } template <typename T, typename ... Ts>auto sum_left_init (T init, Ts... args) return (init + ... + args); } template <typename T, typename ... Ts>auto sum_left_inc (T inc, Ts... args) return (... + (args + inc)); } template <typename T, typename ... Ts>void print_v (T t, Ts... args) ((std::cout << t) << ... << args) << "\n" ; } int main () std::cout << sum_left (1 , 2 , 3 , 4 ) << "\n" ; std::cout << sum_right (1 , 2 , 3 , 4 ) << "\n" ; std::cout << sum_left_init (10 , 1 , 2 , 3 , 4 ) << "\n" ; std::cout << sum_left_inc (5 , 1 , 2 , 3 , 4 ) << "\n" ; print_v ("1" , "2" , "3" , "4" ); }
针对于一些复杂case我们可以这么操作,通过lambda或者抽出一个方法来操作!!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <iostream> #include <vector> #include <algorithm> template <typename T, typename ... Ts>auto append (std::vector<T>& arr, Ts... elems) (..., arr.push_back (elems)); auto append = [&](T elem) { if (elem > 10 ) { arr.push_back (elem); } }; (append (elems), ...); } int main () std::vector<int > arr; append (arr, 1 , 2 , 3 , 4 , 4 , 10 , 11 ); std::for_each(arr.begin (), arr.end (), [](auto elem) { std::cout << elem << "," ; }); }
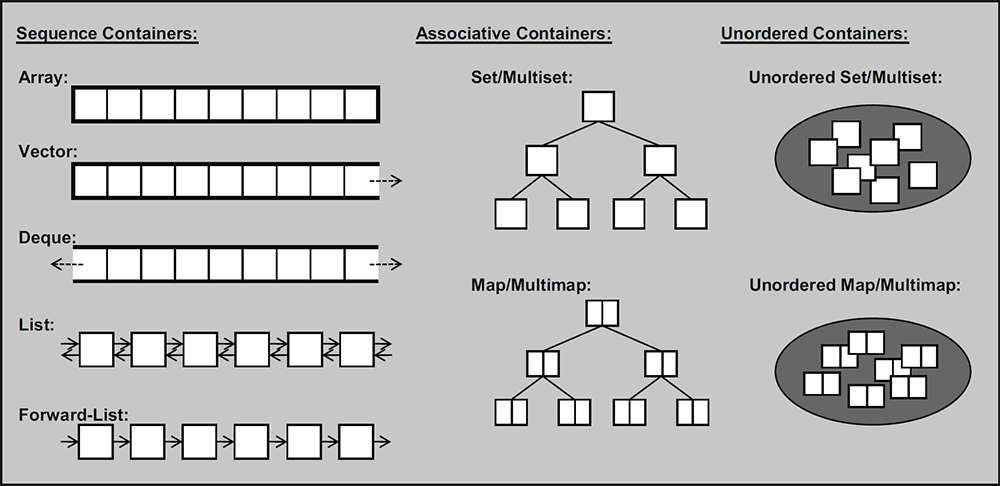
STL STL:(Standard Template Library)叫做C++标准模版库,其实可以理解为C++最核心的部分,很多人望而却步,其实我感觉还好!
主要包含:
容器类模板: 基本的数据结构,数组、队列、栈、map、图 等,如果你学习过很多高级语言,那么对于C++这些容器结构我觉得其实不用太投入,只要熟悉几个API就可以了!
1 2 3 4 5 6 7 8 9 #include <vector> #include <array> #include <deque> #include <list> #include <forward_list> #include <map> #include <set> #include <stack>
算法(函数)模板:基本的算法,排序和统计等 , 其实就是一些工具包 迭代器类模板:我觉得在Java中很常见,因为你要实现 for each 就需要实现 iterator 接口,其实迭代器类模版也就是这个了! 总结 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> #include <algorithm> #include <iterator> #include <vector> template <typename C, typename V>void findAndInsert (C& container, const V& targetVal, const V& insertVal) using std::begin; using std::end; auto it = std::find (begin (container), end (container), targetVal); container.insert (it, insertVal); } int main () auto arr = std::vector<int >{1 , 2 , 3 , 4 }; findAndInsert (arr, 4 , 2 ); std::for_each(arr.begin (), arr.end (), [](decltype (*arr.begin ()) elem) { cout << elem << endl; }); return 0 ; }
现在很多高级语言都支持切片,可以说是大大提高了开发效率,但是cpp也有,也很简单,区别在于是c++实现的是拷贝,而非内存复用,所以这种需求还是用迭代器比较好! 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <iostream> #include <vector> #include <functional> #include <algorithm> using IntVector = std::vector<int >;template <typename T>void print (std::vector<T> &v) int index = 0 ; std::cout << "[" ; for (const auto &item : v) { if (index != 0 ) { std::cout << ", " ; } std::cout << item; ++index; } std::cout << "]" << std::endl; } int main () IntVector v1{}; v1.reserve (10 ); for (int x = 0 ; x < 10 ; x++) { v1.push_back (x); } print (v1); auto v2 = IntVector (v1.begin (), v1.begin () + 4 ); print (v2); auto v3 = IntVector (v1.begin () + 1 , v1.end () - 1 ); print (v3); for (auto begin = v1.begin (); begin != v1.begin () + 4 ; begin++) { std::cout << "range: " << *begin << std::endl; } std::for_each(v1.begin () + 1 , v1.begin () + 4 , [](auto elem) { std::cout << "for_each: " << elem << std::endl; }); }
预处理器 - 宏 宏本质上就是在预处理阶段把宏替换成对应的代码,属于代码模版[ C++/C 思想真的超前 ],可以省去不少代码工作量,其次就是性能更好,不需要函数调用,直接预处理阶段内联到代码中去了,例如我这里就用了宏 https://github.com/Anthony-Dong/protobuf/blob/master/pb_include.h !
宏的玩法太高级,很多源码满满的宏,不介意新手去深入了解!只要能看懂就行了,简单实用一下也完全可以的哈!
简单的例子 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <iostream> #define product(x) x* x using namespace std;int main () int x = product ((1 + 1 )) + 10 ; std::cout << "x: " << x << std::endl; int y = product (1 + 1 ) + 10 ; std::cout << "y " << y << std::endl; #ifdef ENABLE_DEBUG cout << "print debug" << endl; #endif } x: 14 y: 13
class+宏+类名的意义 注意: 这里要是有windows环境的话可以自己体验下!
不清楚大家阅读过c++源码吗,发现开源的代码中基本都有一个 ,那么问题是 PROTOBUF_EXPORT 干啥了?
1 2 3 class PROTOBUF_EXPORT CodedInputStream { }
实际上你自己写代码没啥问题,定不定义这个宏,你要把代码/ddl提供给别人用windows的开发者来说就有问题了,别人引用你的api需要申明一个 __declspec(dllexport) 宏定义,表示导出这个class,具体可以看 https://learn.microsoft.com/en-us/cpp/cpp/using-dllimport-and-dllexport-in-cpp-classes 所以说对于跨端开发来说是非常重要的这点!
其次这个东西很多时候可以在编译器层面做手脚,表示特殊标识,反正 大概你知道 windows 下需求这个东东就行了!
1 2 3 4 5 6 #define DllExport __declspec( dllexport ) class DllExport C { int i; virtual int func ( void ) return 1 ; } };
RTTI 待补充!
多线程 https://en.cppreference.com/w/cpp/thread
cpp11 的 thread、mutex、lock_guard、lock_uniq、feature
cpp14 支持了 shared_lock
cpp17 支持了 async 、shared_mutex
cpp20 支持了 jthread 和 coroutine
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <mutex> #include <thread> #include <iostream> int main () using GuardLock = std::lock_guard<std::mutex>; using UniqueLock = std::unique_lock<std::mutex>; std::mutex mutex; int count = 0 ; { auto test = [&count, &mutex]() { for (int y = 0 ; y < 100000 ; y++) { GuardLock lock (mutex); ++count; } std::cout << std::this_thread::get_id () << ": " << count << std::endl; }; std::jthread tt (test) ; std::jthread t2 (test) ; std::jthread t3 (test) ; } std::cout << "main" << count << std::endl; }
其他 new 与 malloc 我们知道,我们可以再 C语言里使用 malloc 和 frees 初始化内存,但是C++ 里更加推荐使用 new 和 delete ,那么区别在哪里了!
首先我们知道C++引入了 构造函数 和 析构函数,因此我们用 c系列的api操作,会丢失这些信息,这就是最主要的区别,也是特别需要注意的!
例子一: 最常见的乱用行为!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Test { public : explicit Test (int x_) : x(x_) { ~Test () { std::cout << "release: " << x << std::endl; } public : int x; }; int main () Test* test = new Test (1 ); delete test; }
例子二: 业务中为了做一些事情,例如有些特殊case需要用 void* 指针进行操作(例如导出C),解决内存拷贝的问题
1 2 3 4 5 6 7 8 9 10 11 12 struct CClass { void * point; }; int main () Test* test = new Test (1 ); CClass c{ .point = test, }; delete }
new[] 与 delete[] 我们可以简单看下面这个例子,就大概明白了,new与delete的区别
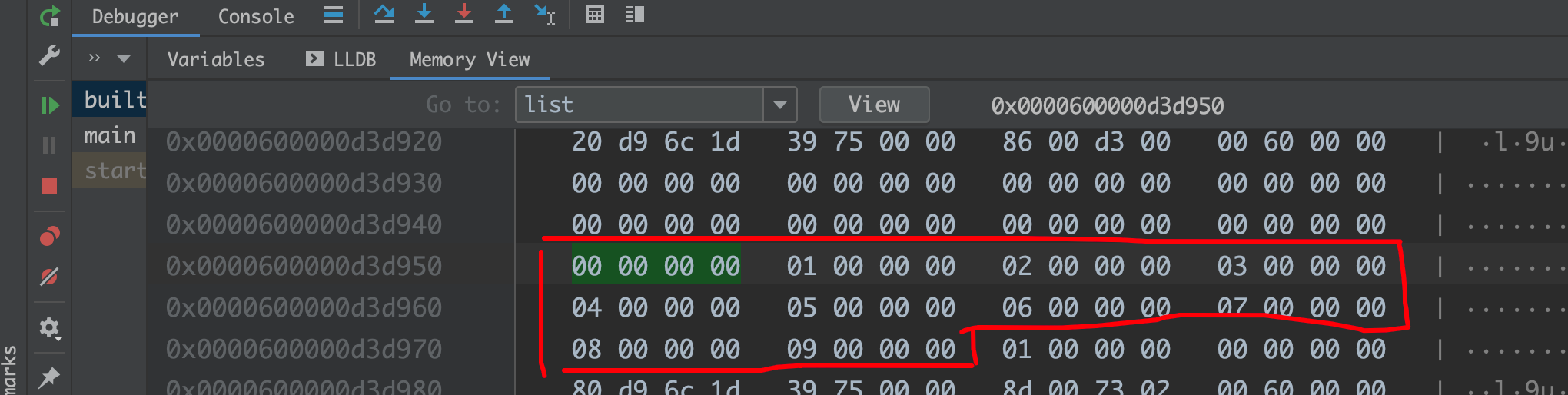
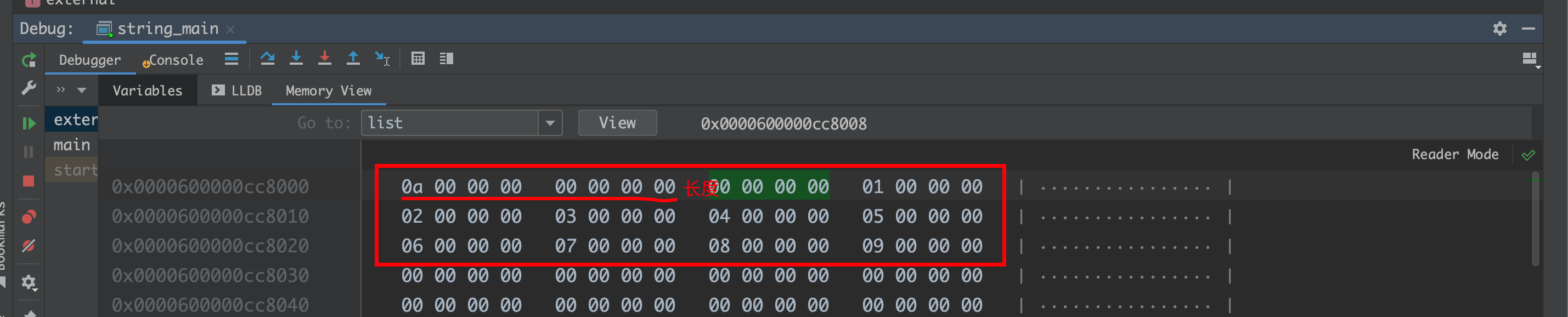
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Test { public : Test () = default ; int x; }; void builtin () auto list = new int [10 ]{}; for (int x = 0 ; x < 10 ; x++) { list[x] = x; } cout << *((unsigned long *)list - 1 ) << endl; delete [] list; } void external () auto list = new Test[10 ]{}; for (int x = 0 ; x < 10 ; x++) { list[x].x = x; } cout << *((unsigned long *)list - 1 ) << endl; delete [] list; }
内置类型的话,内存中不会存储长度字段
其他类型,会在首地址-8 的位置存储长度,也就是64位是8字节
所以对于new[] 的指针对象,一定要用delete[] 释放,不然的话你会内存泄漏奥! C++ 位域 https://learn.microsoft.com/zh-cn/cpp/cpp/cpp-bit-fields?view=msvc-170 可以节约内存开销
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <iostream> using namespace std;struct http_parser { unsigned int type : 2 ; unsigned int flags : 8 ; unsigned int state : 7 ; unsigned int header_state : 7 ; unsigned int index : 5 ; unsigned int uses_transfer_encoding : 1 ; unsigned int allow_chunked_length : 1 ; unsigned int lenient_http_headers : 1 ; uint32_t nread; uint64_t content_length; unsigned short http_major; unsigned short http_minor; unsigned int status_code : 16 ; unsigned int method : 8 ; unsigned int http_errno : 7 ; unsigned int upgrade : 1 ; void *data; }; int main () cout << sizeof }
namespace 我们知道c语言是没有namespace的概念的,作用域是全局的,所以导致头文件如果存在公共定义是可能会存在问题的。
c++ 支持了namespace,解决命名冲突的问题,但是同样的它会造成编译的时候 符号连接会带上namespace,导致c语言无法和c++链接,此时就需要用到 extern "C" 了!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 namespace Misc {namespace Utils {struct Consts {}; } } namespace Misc {namespace Network {struct TcpConnect { using Consts = Utils::Consts; using FullConsts = Misc::Utils::Consts; }; } }
常用库 其他学习资料