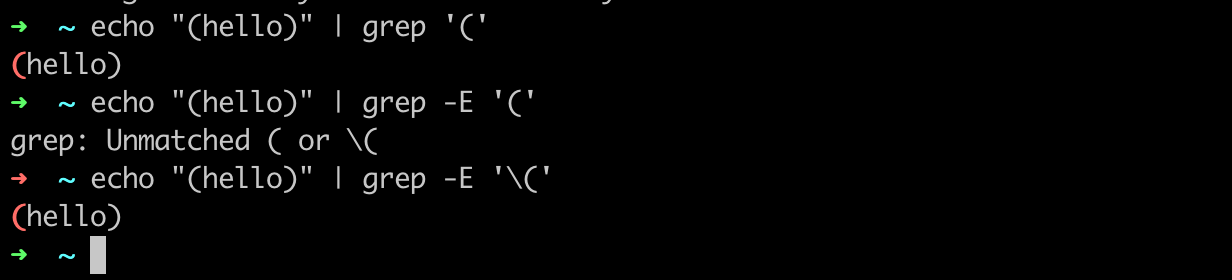grep、awk命令主要是用于我们日常开发中日志检索,问题就是有同学可能会咨询不是有elk、企业内部日志收集过滤系统,那么我为啥要学这些东西!日志收集在系统不稳定的情况下是很容易丢失日志的或者你做一些高精度的过滤日志也不符合,比如我要查看一下latency>10s的接口,你日志咋搜!!所以还是有学习必要性的!
正则表达式如果你业务中处理文本的需求比较多的话,正则表达式的作用不容小觑,而且正则表达式庞大的知识体系也需要经常练习才可以!
1、grep 1. 基础概念 grep全名叫Global regular expression print, wiki: https://zh.wikipedia.org/zh-tw/Grep ,其实就是一个全局的正则表达式过滤然后打印!
2. 日常使用 grep 是我们日常最常见和使用的命令了,主要是做正则匹配做日志过滤!
这里主要介绍一下常用的命令和技巧吧
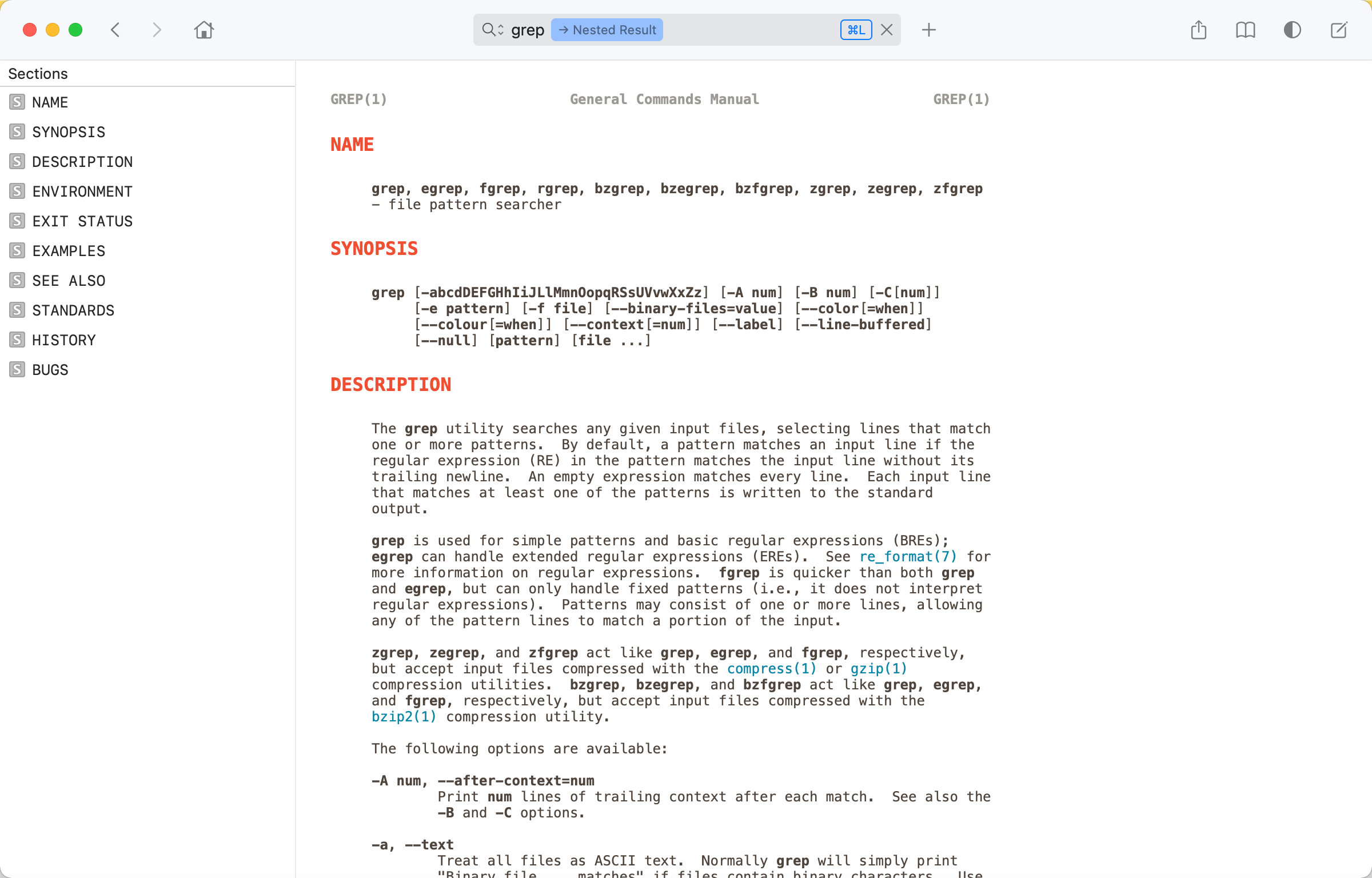
1 2 3 4 grep [-abcdDEFGHhIiJLlMmnOopqRSsUVvwXxZz] [-A num] [-B num] [-C[num]] [-e pattern] [-f file] [--binary-files=value] [--color[=when]] [--colour[=when]] [--context[=num]] [--label] [--line-buffered] [--null] [pattern] [file ...]
简单匹配就是 cat biz.log | grep 'Error' 过滤所有包含Error的行
-i 可以忽略大小写,比如上面的grep -i error 它可以匹配 error和Error 等!-v 取反,比如说grep -v 'error',那么他就可以取info、debug、warn的日志了--colour=auto|always|never,一般设置为 --colour=always 就可以高亮展示了!-E 是高级正则,比如一些高级的正则 .或则\w ,\d 等,就需要了-F为fgrep 其实就是--fixed-strings 本质上就是对于正则表达式不进行转义,比如
3. 使用案例 查找目录下关键词 1 2 3 4 5 6 7 # 查看当前目录下存在`QuoteType` 关键词的文件 ~ grep -r 'QuoteType' ./ ./diversity.proto: optional QuoteType quoteType = 1; // 引用类型 # 仅展示文件 ~ grep -rl 'QuoteType' ./ ./diversity.proto
4. 总结 所以一般你是精确字符匹配的话,推荐用 grep -F 或者fgrep , 如果你用的是正则匹配的话推荐用egrep和grep -E , 具体差异可以下我下面正则表达式那个章节 !
4. 参考文章 2、awk awk 是三个大佬写的一门语言,说是一门语言其实不足为过!因为确实贼厉害!
1. 基础概念介绍 awk 整体格式就是有一组的 pattern-action组成,不过也有可能只有action,但是必须要知道这一点很重要!!
备注: 下列例子可能用到 out.log文件,文件内容如下:
1 2 3 4 5 Dan 3.75 0 Kathy 4.00 10 Mark 5.00 20 Mary 5.50 22 Susie 4.25 18
简单过滤模式 (pattern-action) 1 2 3 4 5 6 7 8 awk '$3>0 {print}' # pattern 就是 $3 >0 , {print } 表示行为, 如果不指定 pattern 那么表示无过滤条件, # 换成其他语言就是 for x:=0; x<len; x++{ if (pattern) { action() } }
(action1) (action2)模式1 2 3 4 5 6 awk '{print} {print}' # 转换后 for x:=0; x< len; x++{ action1() action2() }
内置pattern模式, pattern=BEGIN / END 1 2 3 4 5 6 7 8 9 10 11 12 13 # pattern=END,表示结束 awk 'END {print}' # 换成其他语言就是 for x:=0; x<len; x++{ } action() # pattern=BEGIN,表示开始 awk 'BEGIN {print}' # 换成其他语言就是 action() for x:=0; x<len; x++{ }
输出函数 1 2 3 4 5 awk '{print 1, $1; print 2, $1}' awk '{print 1, $1} {print 2,$1}' awk '{printf "1 %s\n", $1; printf "2 %s\n", $1}' ... # 上诉例子输出其实是一样的!
if / else 前面虽然说了 pattern可以支持条件过滤,但是太过于简单!不支持else语句
1 2 3 4 5 6 7 ➜ yulili cat out.log | awk '{if ($3>0) printf "%s-%d gt 0\n", $1, $3; else printf "%s-%d eq 0\n", $1,$3}' Beth-0 eq 0 Dan-0 eq 0 Kathy-10 gt 0 Mark-20 gt 0 Mary-22 gt 0 Susie-18 gt 0
for 循环 ,一般会在END语句中执行!1 2 3 4 5 6 ➜ yulili cat out.log | awk 'END { for (x=1; x<NR; x++) printf "row %d\n", x}' row 1 row 2 row 3 row 4 row 5
数组/map , 可以通过 var[index]=value或者var[key]=value 进行定义!同时可以通过 in进行判断是否存在 1 2 3 4 5 6 7 8 9 10 11 # 简单的便利循环 ➜ yulili cat out.log | awk '{line[NR]=$0} END { for (x=1; x<NR; x++) printf "row: %s\n", line[x]}' row: Beth 4.00 0 row: Dan 3.75 0 row: Kathy 4.00 10 row: Mark 5.00 20 row: Mary 5.50 22 # 判断是否存在 ➜ yulili cat out.log | awk '{line[NR]=$0} END {if (1 in line) print "1 in line"} END {if (0 in line) print "0 in line"}' 1 in line
正则匹配 1 2 3 4 5 6 7 8 9 10 11 # 例如输出M开头的用户信息 ➜ yulili cat out.log| awk '$1 ~ "^M" {print}' Mark 5.00 20 Mary 5.50 22 # 例如输出非M开头的用户信息 ➜ yulili cat out.log| awk '$1 !~ "^M" {print}' Beth 4.00 0 Dan 3.75 0 Kathy 4.00 10 Susie 4.25 18
内置变量 内置变量 含义 NR(numeric row) 表示总行数,已经阅读的行数, BEGIN=0,END=total NF(number field) 表示没行的列数,BEGIN=0, END=pre_row_column FS (field separator) 输入的分隔符,默认应该是 " " OFS(out field separator) 输出的分隔符,默认是" " $0…n 变量,$0表示整个列,$1表示第一列,注意变量是可以被修改 !
例如我修改FS和OFS, FS为空格,输出的OFS是, 1 2 3 4 5 6 7 ➜ yulili cat out.log | awk 'BEGIN { FS=" "; OFS=","} {print $1 ,$2 ,$3}' Beth,4.00,0 Dan,3.75,0 Kathy,4.00,10 Mark,5.00,20 Mary,5.50,22 Susie,4.25,18
内置函数 内置函数 含义 print 换行输出, eg: awk '{print $1, $2, $3; print $1, $2}' printf format输出, eg: awk '{printf "第一列: %d", $1}' length(s) s为字符串,输出字符串长度 substr(s,p) s为字符串,p为index,输出从index后截取的字符串 gsub(r,s,t) 将字符串t中的 r 替换为s, 输出字符串 strtonum(s) s为字符串,输出为numeric rand() 输出一个随机数 int(x) 输出x的整数部分
例如我们使用gsub函数替换,这里可能注意可以正则替换 1 2 3 4 5 6 7 ➜ yulili cat out.log| awk '{gsub("\\.","0",$2)}{print $2}' 4000 3075 4000 5000 5050 4025
2. 简单例子介绍 查询工时大于0的记录 1 2 3 4 5 ➜ yulili cat out.log | awk '$3>0 {print}' Kathy 4.00 10 Mark 5.00 20 Mary 5.50 22 Susie 4.25 18
查询工时大于0的人员数量 , 业务中比较适合过滤 latency > xxxms的数量! 1 2 ➜ yulili cat out.log | awk '$3>0 {emp=emp+1} END {printf "total emp: %d\n", emp}' total emp: 4
查询平均工资 (工时*工时费用/ 人员) , 其实吧业务中比较适合求avg-latency 1 2 ➜ yulili cat out.log | awk '{ salary = salary + $2*$3 } END { printf "avg salary: %d\n", salary / NR }' avg salary: 56
3. 使用技巧技巧 比如经常出现我们要检查 latency > xxx 的access_log ,怎么解决了,由于我们日志中 latency是这么记录的cost=251045,那么我们在过滤的时候需要字符串操作,这时候需要substr(str, index) 函数取出来lantency,然后取出来实际上是字符串类型,那么此时需要通过+0来转换为int!! 或者通过函数 strtonum进行转换, 下面例子是取出大于200ms的日志的logid 1 2 3 4 5 6 7 8 9 10 11 # cat access.log | awk 'strtonum(substr($11,6)) > 200000 {print $6 ,$11, substr($11,6)}' # cat access.log | awk 'substr($11,6)+0 > 200000 {print $6 ,$11, substr($11,6)}' 20220312000212010212043169032F1158 cost=358144 358144 20220312000442010150139043227E02C8 cost=251045 251045 20220312002645010150132075097C7676 cost=532952 532952 2022031200293601021009615805605CF5 cost=256238 256238 20220312002943010211182012276F60AD cost=298612 298612 2022031200295801021009615805606647 cost=213975 213975 20220312003410010150135045168607FA cost=366926 366926 202203120037310101501390291691A893 cost=4882332 4882332 202203120039100101501322000F82B0D0 cost=276756 276756
文本处理,例如以下文本 需求是需要按, 分割,且要拼接字符串!如 a,b,c 需要输出 t1.a=t2.a and t1.b=t2.b and t1.c=t2.c , 可以下面这么写!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 cat text.txt| awk ' BEGIN { FS="," } $ 0 ~ /\S/ { sql="" for (x=1;x<=NF;x++) { if ( x != NF ){ sql= sprintf ("%s a.%s=b.%s and",sql, $x, $x) }else{ sql= sprintf ("%s a.%s=b.%s", sql, $x, $x) } } sqls[NR]=sql } END { for (x=1;x<=NR;x++){ if ( x in sqls) { printf "sql: %s\n", sqls[x] # todo 拼接sql } } } '
4. 参考文章 3、sed 1. 基础学习 sed全名叫stream editor,流编辑器,用程序的方式来编辑文本。sed基本上就是玩正则模式匹配,所以,玩sed的人,正则表达式一般都比较强。其次就是gun的sed函数和mac的sed是有些不同的,mac上玩sed推荐用gsed!
这里我就介绍一些简单的用法,比如我们经常进行的批量替换比如把代码中某个变量名替换为另一个变量名,或者配置文件之类的,或者进行简单的文本操作!
替换 ,用法就是 sed 's/a/b/g' file, 意思就是把a替换为b,全局替换1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 ➜ docs cat test.log aaaaaa bbbbbb aaaaaa cccccc # 把a替换成b,每行第一个 ➜ docs cat test.log| sed 's/a/b/' baaaaa bbbbbb baaaaa cccccc # 最后加一个g表示global的意思,表示每行全局替换! ➜ docs cat test.log| sed 's/a/b/g' bbbbbb bbbbbb bbbbbb cccccc # 表示从第三个字符开始替换 ➜ docs cat test.log| sed 's/a/b/3g' aabbbb bbbbbb aabbbb cccccc # s 可以通过[start,end]来修饰行数,比如 1-3行可以 1,3s, 比如1行可以1s,末尾行可以 $s , 比如2-最后一行可以用2,$表示 ➜ docs cat test.log| sed '1,3s/a/b/g' bbbbbb bbbbbb bbbbbb cccccc # 只替换第一行 ➜ docs cat test.log| sed '1s/a/b/g' bbbbbb bbbbbb aaaaaa cccccc # 只替换最后一行 ➜ docs cat test.log| sed '$s/c/a/g' aaaaaa bbbbbb aaaaaa aaaaaa
注意:如果你要使用单引号,那么你没办法通过\这样来转义,就有双引号就可以了,在双引号内可以用\”来转义。
正则替换 ,但是一般推荐使用正则直接携带 -E参数,注意会有一些转义字符,需要通过\来处理1 2 3 4 5 ➜ docs cat test.log| sed -E '2,$s/\w/a/g' aaaaaa aaaaaa aaaaaa aaaaaa
添加/插入/删除/替换文本 , sed 'a1 文本'也就是在第一行后面添加文本,sed 'i1 文本'含义就是在第一行插入文本a: append i: insert d: delete 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 # 在第一行后面添加zzzzzz ➜ docs cat test.log | sed '1a zzzzzz' aaaaaa zzzzzz bbbbbb aaaaaa cccccc # 在最后一行添加`zzzzzz` ➜ docs cat test.log | sed '$a zzzzzz' aaaaaa bbbbbb aaaaaa cccccc zzzzzz # 第一行插入 `zzzzzz` ➜ docs cat test.log | sed '1i zzzzzz' zzzzzz aaaaaa bbbbbb aaaaaa cccccc # 删除第一行和最后一行! ➜ docs cat test.log | sed '1d;$d' bbbbbb aaaaaa
截取文本 1 2 3 4 5 6 7 8 9 10 11 12 13 # 选择第2-3行文本,注意这里必须加-n参数,否则会重复打印 ➜ docs cat test.log| sed -n '2,3p' bbbbbb aaaaaa # 打印 ➜ docs cat test.log| sed -n '/b/p' bbbbbb # 打印b或者c的文本 ➜ docs cat test.log| sed -n '/\(\(b\|c\)\)/p' bbbbbb cccccc
2. 总结 命令通用格式 [addr]/[regexp]/[flags] 或者 [addr]/[regexp]/[replace content]/[false] 多个命令可以通过 ;进行分割 2addr表示可以通过 1,2进行选择行操作1addr只支持1或者$或者 ….sed -i 是直接替换原文本!所以不推荐这么使用,可以用重定向符号进行操作!sed -E 表示使用拓展正则!如果你使用正则则推荐使用这个!mac 上推荐使用gsed命令! 命令 备注 [2addr]s/regular expression/replacement/flags 把regular expression替换成replacement w file 写入到file中 r file 读取文件 [2addr]x 清空某行 1x表示清空第一行, Swap the contents of the pattern and hold spaces. [1addr]a text apped text [1addr]i text insert text [2addr] d delete 指定行 /regexp/d删除匹配行 -n '[2addr]p'print 打印指定行 -n /regexp/p打印匹配行
3. 参考文章 4、Dash 如果你用的是mac作为你的开发环境,我推荐你使用dash进行命令或者代码库检索!比较好用,因为平时比如我们经常遇到写代码忘记api的,可以通过dash进行搜索!
不过Linux的GNU命令都会携带帮助的!看个人喜好吧!
5、 正则表达式 其实不难发现,只要文本处理就离不开 正则表达式 (Regular Expression) ,可能有些同学会说 通配符(wildcard) ,确实通配符可以解决一部分问题,但是还是有些时候还是正则更加强大和灵活,其实通配符是正则表达式的前身,出生更早!
1. 通配符 * 匹配零个或多个字符 (有点像数据库的通配符*)
? 匹配任意一个字符(有点像数据库的通配符_)
[char_list] 匹配char_list中任意单个字符
[^char_list] or [!char_list] 排除 char_list中任意一个字符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ➜ test_file ls *.file a.file ab.file c.file cd.file ➜ test_file ls -a ./ ../ a.file ab.file c.file cd.file ➜ test_file ls *.file a.file ab.file c.file cd.file ➜ test_file ls [a].file a.file ➜ test_file ls [a]?.file ab.file ➜ test_file ls [a]*.file a.file ab.file ➜ test_file ls [ac]*.file a.file ab.file c.file cd.file ➜ test_file ls [^a].file c.file ➜ test_file ls [^a]*.file c.file cd.file
{xxx1,xxx2,xxx3} 只能是 xxx1 or xxx2 or xxx3 , 模式, 这个比较常见主要用作创建文件ls文件1 2 3 4 5 6 7 ➜ test_file ls {a,ab}.file a.file ab.file ➜ test_file ls {a,c}*.file a.file ab.file c.file cd.file ➜ test_file touch d{a,b,c,d}.file ➜ test_file ls d{a,b,c,d}.file da.file db.file dc.file dd.file
{start..end} 表示匹配 start->end 中的字符, 比较适合for循环!!其中支持数字和字母1 2 3 4 5 6 7 8 9 10 11 ➜ test_file for x in {1..10}; do echo "num: ${x}"; done num: 1 num: 2 num: 3 num: 4 num: 5 num: 6 num: 7 num: 8 num: 9 num: 10
最后介绍下 通配符执行原理,通配符顾名思义就是执行的实现先进行解释,也就是比如 ls *.file 先解析成ls a.file 再执行 ls a.file, 假如没有匹配会导致报错或者程序不符合预期
2. 正则表达式一 (基础) 基础感觉不用说,可以看下 https://github.com/Anthony-Dong/learn-regex-zh , 想必看这篇文章的人正则基本都还是可以的! 这里推荐一个正则表达式的可视化网站 https://regexper.com/
元字符,这类字符会有特殊含义,所以如果你正则中想要不表示特殊含义就需要转义 了! 以下列表 POSIX Extended 和 Perl 全部支持 !POSIX 部分不支持! 元字符 描述 . 匹配除换行符以外的任意字符。 [ ] 字符类,匹配方括号中包含的任意字符。 [^ ] 否定字符类。匹配方括号中不包含的任意字符 * 匹配前面的子表达式零次或多次 + 匹配前面的子表达式一次或多次 ? 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。 {n,m} 花括号,匹配前面字符至少 n 次,但是不超过 m 次。 (xyz) 字符组,按照确切的顺序匹配字符 xyz。 | 分支结构,匹配符号之前的字符或后面的字符。 \ 转义符,它可以还原元字符原来的含义,允许你匹配保留字符 `[ ] ( ) { } . * + ? ^ $ \ ^ 匹配行的开始 $ 匹配行的结束
简写字符集,这个比较常用,因为确实这类简写字符集很方便,省代码! 以下只要 Perl 全部支持,POSIX 支持不友好! 简写 描述 . 匹配除换行符以外的任意字符 \w 匹配所有字母和数字的字符:[a-zA-Z0-9_] \W 匹配非字母和数字的字符:[^\w] \d 匹配数字:[0-9] \D 匹配非数字:[^\d] \s 匹配空格符:[\t\n\f\r\p{Z}] \S 匹配非空格符:[^\s]
3. 正则表达式二 (分组) 说实话,业务中我遇到分组的情况也不少,但是大多数人也基本不会用,也就是写个基础正则罢了!分组作用就是将正则分为多个组,然后我们可以取每个组内部的东西!举个例子,比如我要匹配一个文本 2020年 01月 02日 ,我要第一匹配,第二取出来年月日!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import ( "regexp" "testing" "github.com/anthony-dong/go-sdk/commons" "github.com/stretchr/testify/assert" ) func TestMatch (t *testing.T) re := regexp.MustCompile(`^\d+年\s*\d{1,2}月\s*\d{1,2}日$` ) assert.Equal(t, re.MatchString("2020年 01月 02日" ), true ) assert.Equal(t, re.MatchString("2020年01月02日" ), true ) assert.Equal(t, re.MatchString("2020年 01月 02日" ), true ) assert.Equal(t, re.MatchString("01月02日" ), false ) } func TestGroup (t *testing.T) re := regexp.MustCompile(`^(\d+)年\s*(\d{1,2})月\s*(\d{1,2})日$` ) result := re.FindStringSubmatch("2020年 01月 02日" ) t.Logf("%#v\n" , result) assert.Equal(t, len (result), 4 ) t.Logf("年: %s, 月 %s, 日: %s\n" , result[1 ], result[2 ], result[3 ]) } func TestNameGroup (t *testing.T) re := regexp.MustCompile(`^(?P<year>\d+)年\s*(?P<month>\d{1,2})月\s*(?P<day>\d{1,2})日$` ) result := re.FindStringSubmatch("2020年 01月 02日" ) names := re.SubexpNames() for _, elem := range names { t.Logf("sub exp name: %s\n" , elem) } mapData := make (map [string ]string ) for index, elem := range names { if index == 0 { continue } mapData[elem] = result[index] } t.Logf("%s\n" , commons.ToJsonString(mapData)) }
不过Go语言也提供了一些高阶用法,这里根据需求进行使用!
1 2 3 4 5 # re 表示正则表达式 (re) 最简单的分组使用法,通过index获取 (?P<name>re) 可以对分组进行命名 (?:re) 不会对当前分组进行捕获 (?flags) 设置当前所在分组的标志,不捕获也不匹配
4. 正则表达式标准分类 正则表达式也是经历了不断的发展,目前日趋完善,目前主流计算机高级语言都是使用的perl标准,未来perl也会成为正则表达式的标准(不过目前就是)!但是说是标准但是毕竟还是有些工具仍然使用POSIX! 所以我们讲一下区别!
POSIX or BRE( Basic Regular Expression) POSIX Extended or ERE (Extended Regular Express) Perl or PCRE (Perl Compatible Regular Expression) 目前常见的grep 就是用的 POSIX 标准,而 grep -E 或者 egrep 就是用的 POSIX Extended 标准了!像linux命令目前基本上都是走的POSIX 标准,有些可能会拓展POSIX Extended ! 主要区别就是转义字符的区别了, 像POSIX 的转义字符有 .、\、[、^、$、* , 但是 POSIX Extended 多了7个需要转义的字符 (、)、{、}、+、?、| 其实说白了就是不支持 字符组和花括号还有 +和? !
Perl 和 POSIX主要区别也很简单, 就是不支持简写字符集 !但是Go语言好像是POSIX完全不允许简写字符集!所以假如我们使用POSIX还是不用简写字符集吧! 1 2 3 4 5 6 7 8 9 10 11 12 func TestPOSIX (t *testing.T) assert.Equal(t, regexp.MustCompilePOSIX(`^[0-9]+` ).MatchString("123abc" ), true ) assert.Equal(t, assert.Panics(t, func () regexp.MustCompilePOSIX(`^[\d]+` ).MatchString("123abc" ) }), true ) } func TestPerl (t *testing.T) assert.Equal(t, regexp.MustCompile(`^[\d]+` ).MatchString("123abc" ), true ) }
5. 总结 总结一些,假如我们现在要写一个正则,那么需要确定是否使用Perl,如果不是那么我们需要确认是否支持 POSIX Extended !然后就是我们别用简写字符集就行了!
还有断言我没有讲到,所以这里就偷懒了!后续补充!日常中确实没用到断言!
6. 参考文章 7. bash bash 和sh的区别在于,sh遵守POSIX标准,这里我们一般都使用bash,其次大部分命令的话推荐使用 posix (mac上很多命令并不遵守posix)